
|
Haonan Chen I am a postdoctoral researcher in the Embodied Minds Lab at Harvard, working with Yilun Du. I also collaborate closely with Jiajun Wu at Stanford's Vision and Learning Lab and with Ted Adelson at MIT. I received my Ph.D. from the University of Illinois Urbana-Champaign, where I was advised by Katie Driggs-Campbell and collaborated closely with Yunzhu Li. My research focuses on multi-modal action composition — building generalizable robot behaviors by composing specialized models across sensory modalities and time scales.
I'm always excited to explore new collaborations in robotics and machine learning! If you're interested, please drop me an email. I'd love to chat! haonan_chen [at] seas (dot) harvard (dot) edu / haonan [at] cs (dot) stanford (dot) edu |
News
|
Publications |
|
|
CoStream: Composing Simple Behaviors for Generalizable Complex Manipulation
Haonan Chen*, Yuxiang Ma*, Stephen Tian, Xiaoshen Han, Wenlong Huang, Feiyang Wu, Yunzhu Li, Jiajun Wu, Edward H. Adelson, Yilun Du * Equal contribution Preprint 2026, [Project] [Paper] [BibTeX] |
|
OAT: Ordered Action Tokenization
Chaoqi Liu, Xiaoshen Han, Jiawei Gao, Yue Zhao, Haonan Chen, Yilun Du RSS 2026, [Project] [Paper] [Code] [Blog] [BibTeX] Finalist - Best/Outstanding Paper Awards Media Coverage: [MarkTechPost] |

|
IMPACT: Learning Internal-Model Predictive Control for Forceful Robotic Manipulation
Jiawei Gao, Chaoqi Liu, Peilin Wu, Haonan Chen, Yilun Du Preprint 2026, [Project] [Paper] [Code] [Video] [BibTeX] |
|
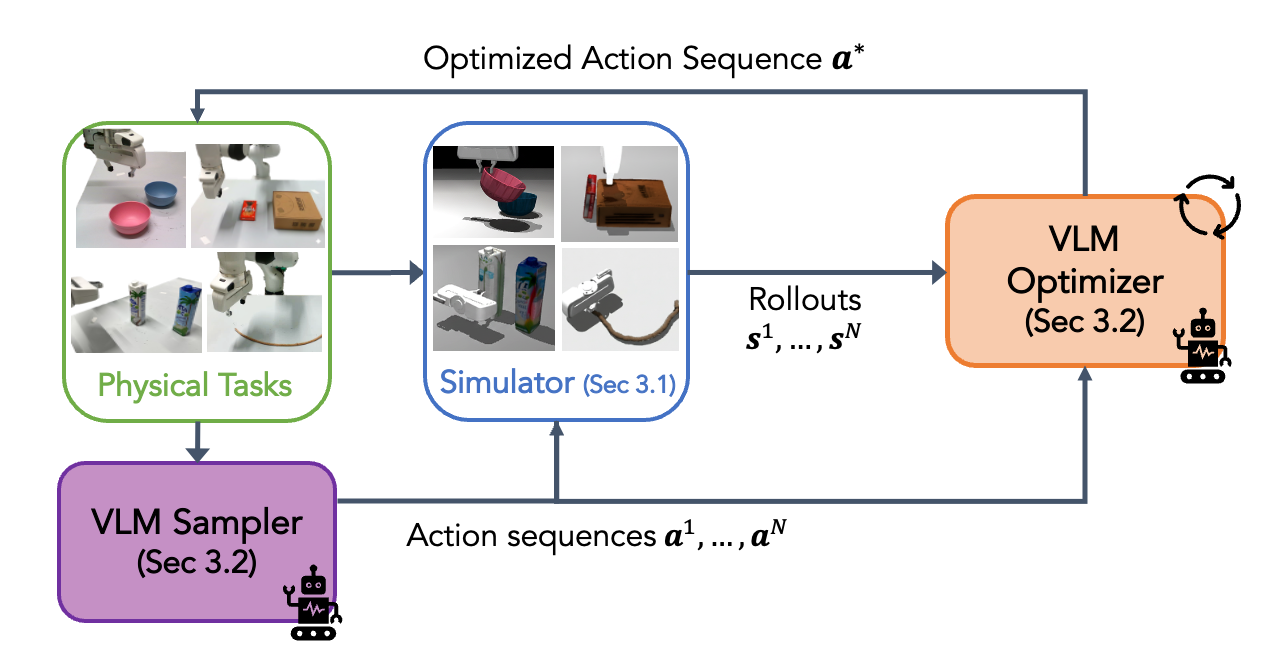
SIMPACT: Simulation-Enabled Action Planning using Vision-Language Models
Haowen Liu*, Shaoxiong Yao*, Haonan Chen, Jiawei Gao, Jiayuan Mao, Jia-Bin Huang, Yilun Du * Equal contribution CVPR 2026, [Project] [Paper] [BibTeX] |
|
|
Multi-Modal Manipulation via Multi-Modal Policy Consensus
Haonan Chen, Jiaming Xu*, Hongyu Chen*, Kaiwen Hong, Binghao Huang, Chaoqi Liu, Jiayuan Mao, Yunzhu Li, Yilun Du+, and Katherine Driggs-Campbell+ * Equal contribution, + Equal advising ICRA 2026, [Project] [Paper] [Code] [Dataset] [Video] [Audio] [Blog] [Deepwiki] [BibTeX] Best Paper Award at CVPR 2026 Workshop on Multi-Sensory Modeling for Embodied Intelligence [Link] Media Coverage: Featured in Video Friday on [IEEE Spectrum] |
|
|
Flexible Multitask Learning with Factorized Diffusion Policy
Chaoqi Liu, Haonan Chen, Sigmund H. Høeg*, Shaoxiong Yao*, Yunzhu Li, Kris Hauser, Yilun Du * Equal contribution RA-L 2026, [Project] [Paper] |
|
|
Tool-as-Interface: Learning Robot Policies from Observing Human Tool Use
Haonan Chen, Cheng Zhu, Shuijing Liu, Yunzhu Li, and Katherine Driggs-Campbell CoRL 2025, [Project] [Paper] [Code] Best Paper Award at ICRA 2025 Workshop on Foundation Models and Neuro-Symbolic AI for Robotics [Link] Best Presentation Award at CSL Student Conference 2025 [Link] Media Coverage: Featured in Video Friday on [IEEE Spectrum] Media Coverage: [The Grainger College of Engineering], [TechXplore], [Hackster.io] |
|
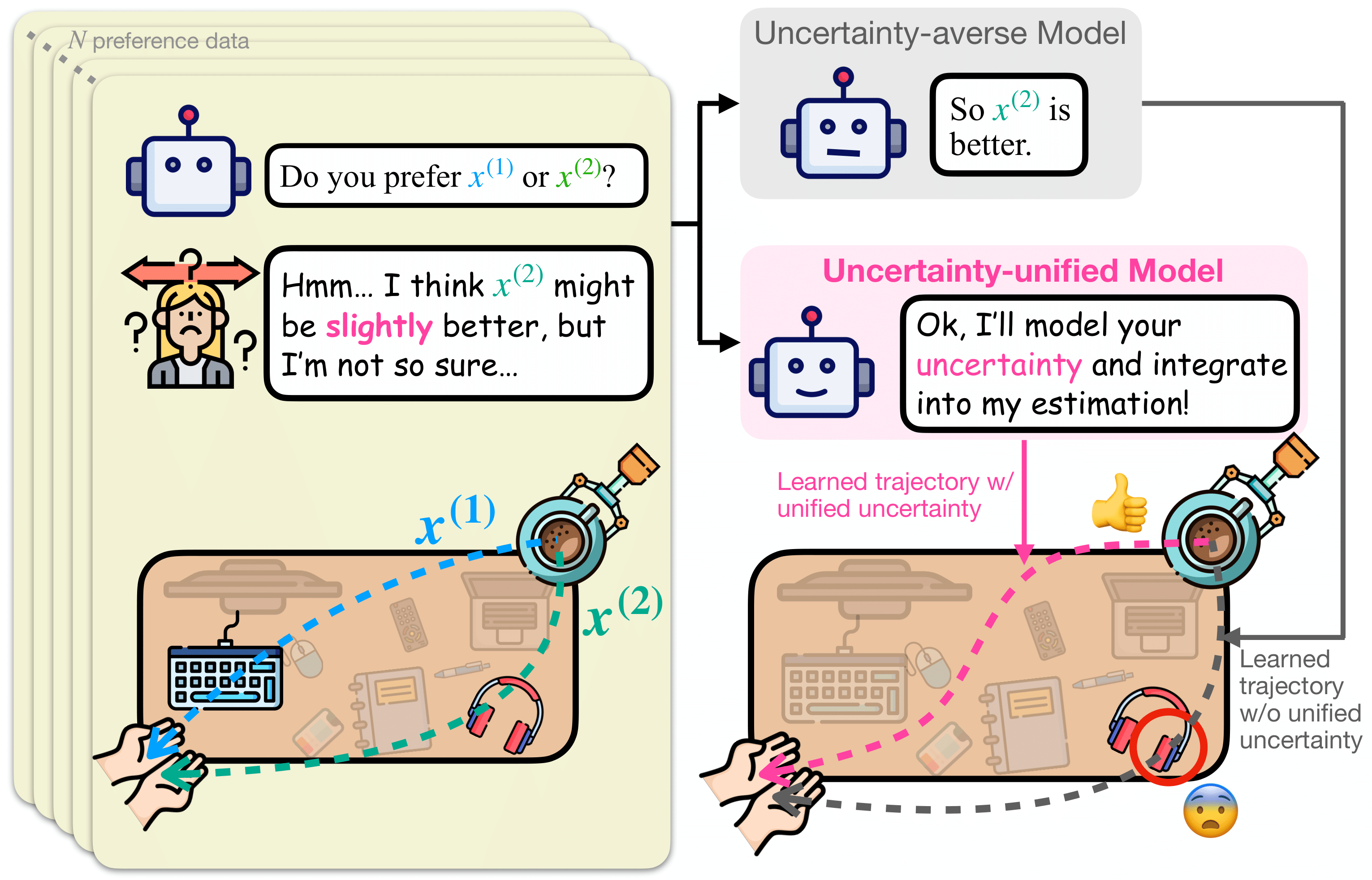
Towards Uncertainty Unification: A Case Study for Preference Learning
Shaoting Peng, Haonan Chen, and Katherine Driggs-Campbell RSS 2025, [Project] [Paper] [Code] [Video] Best Paper Award at ICRA 2026 Workshop on Uncertainty in Open-World Robotics |
|
|
Learning Coordinated Bimanual Manipulation Policies using State Diffusion and Inverse Dynamics Models
Haonan Chen, Jiaming Xu*, Lily Sheng*, Tianchen Ji, Shuijing Liu, Yunzhu Li, and Katherine Driggs-Campbell ICRA 2025, [Project] [Paper] |
|
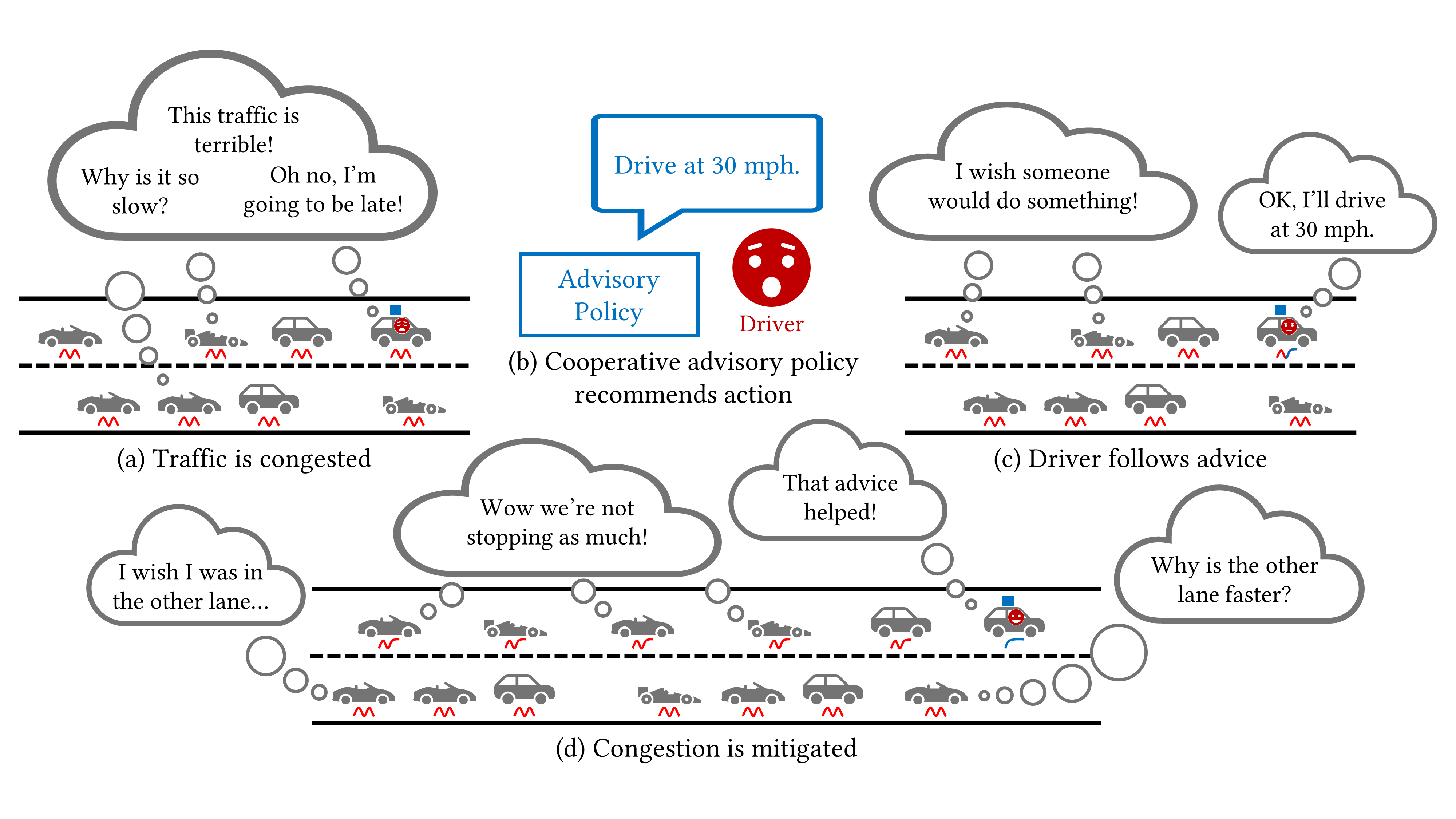
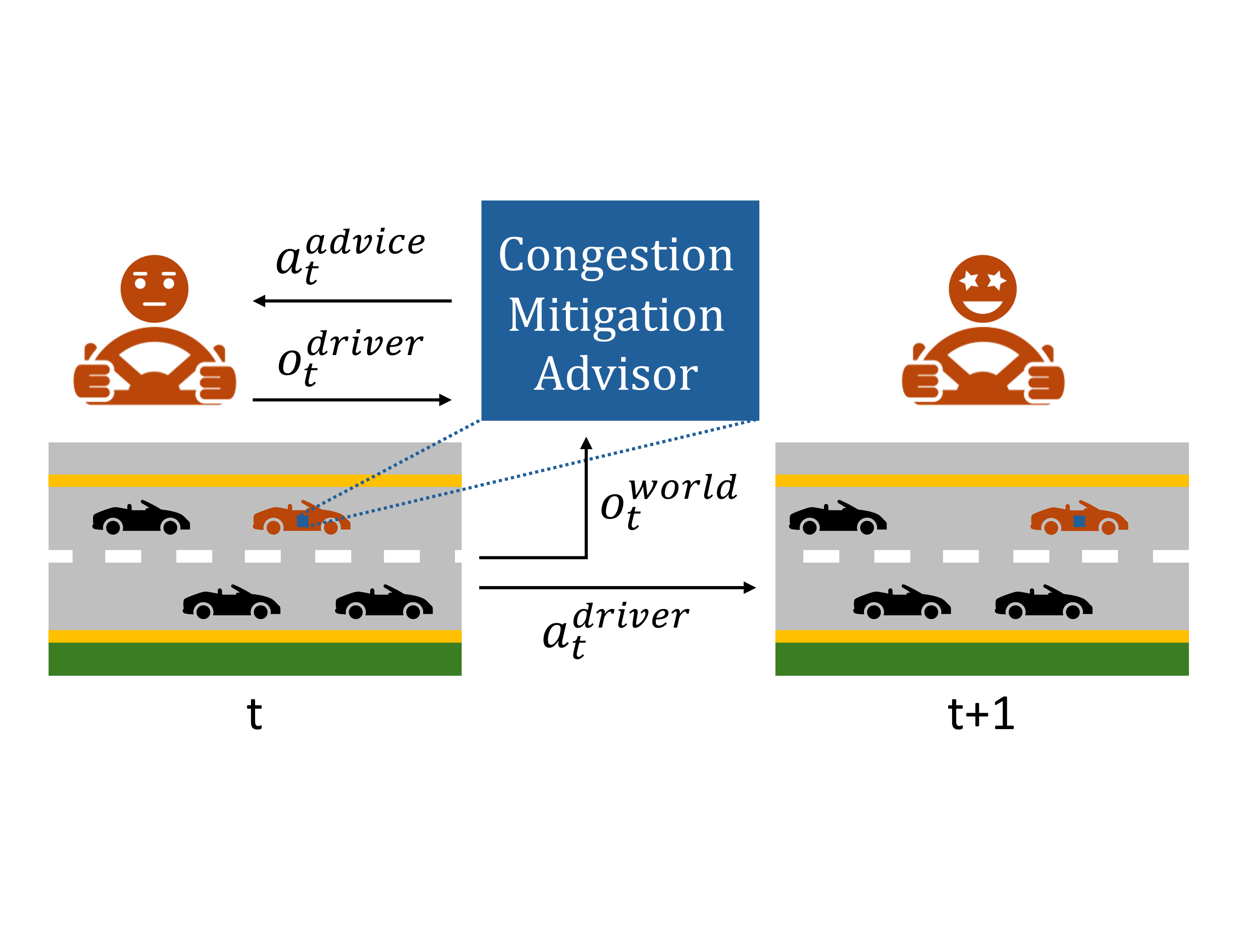
Cooperative Advisory Residual Policies for Congestion Mitigation
Aamir Hasan, Neeloy Chakraborty, Haonan Chen, Jung-Hoon Cho, Cathy Wu, and Katherine Driggs-Campbell JATS 2024, [Paper] |
|
Lessons in Cooperation: A Qualitative Analysis of Driver Sentiments towards real-time Advisory Systems through a Focus Group User Study
Aamir Hasan, Neeloy Chakraborty, Haonan Chen, Jung-Hoon Cho, Cathy Wu, and Katherine Driggs-Campbell ITSM 2024, [Paper] |
|
|
Predicting Object Interactions with Behavior Primitives: An Application in Stowing Tasks
Haonan Chen, Yilong Niu*, Kaiwen Hong*, Shuijing Liu, Yiqing Wang, Yunzhu Li, and Katherine Driggs-Campbell CoRL 2023, [Project] [Paper] Finalist - Best Paper/Best Student Paper Awards |
|
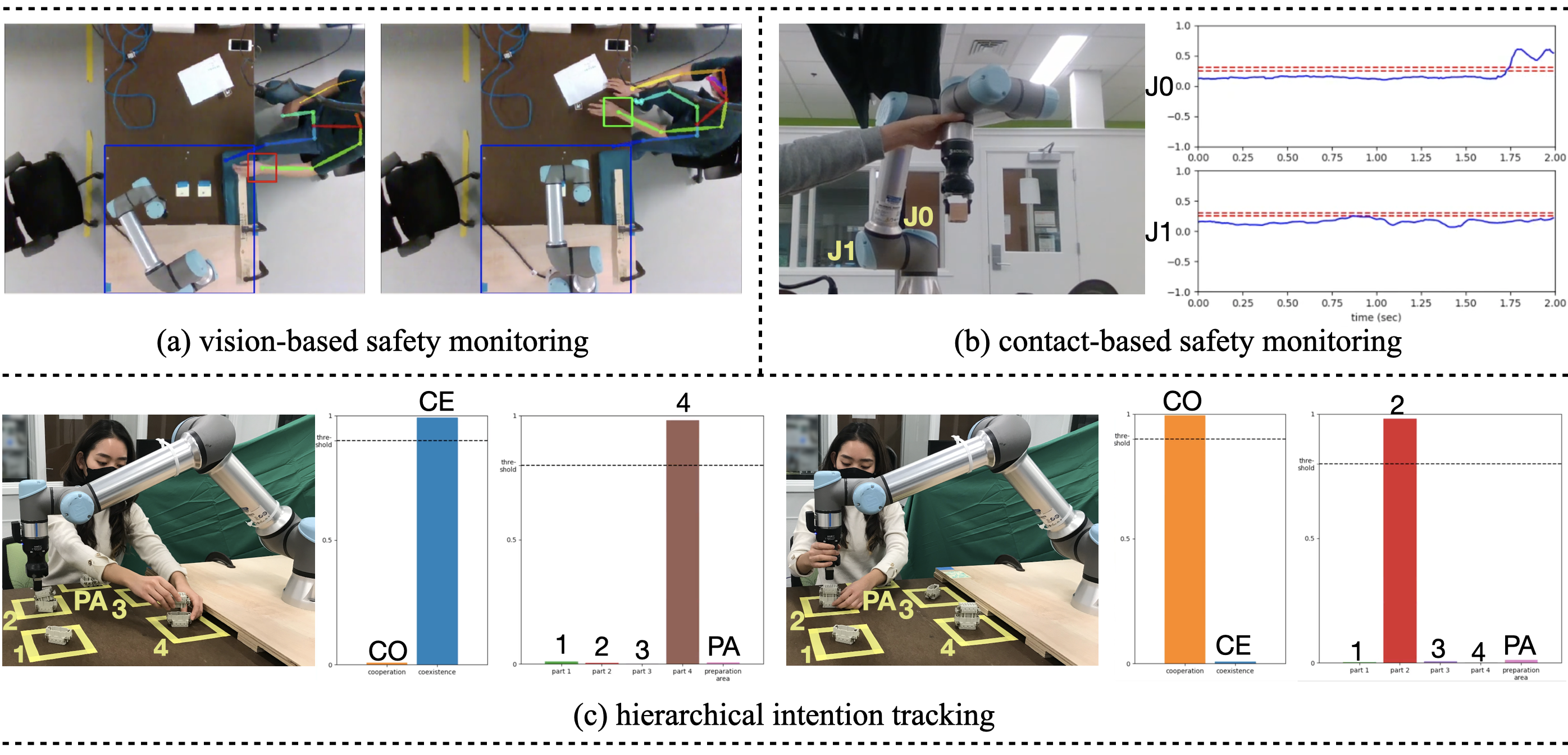
Towards Safety of Multi-Level Human-Robot Interaction in Industrial Tasks
Zhe Huang, Yeji Mun, Haonan Chen, Yiqing Xie, Yilong Niu, Xiang Li, Ninghan Zhong, Haoyuan You, Daniel L. McPherson, and Katherine Driggs-Campbell CASE 2023 (Special Session), [Paper] |

|
Learning Task Skills and Goals Simultaneously from Physical Interaction
Haonan Chen*, Yeji Mun*, Zhe Huang, Yilong Niu, Yiqing Xie, D. Livingston McPherson, and Katherine Driggs-Campbell CASE 2023 (Special Session), [Paper] |
|
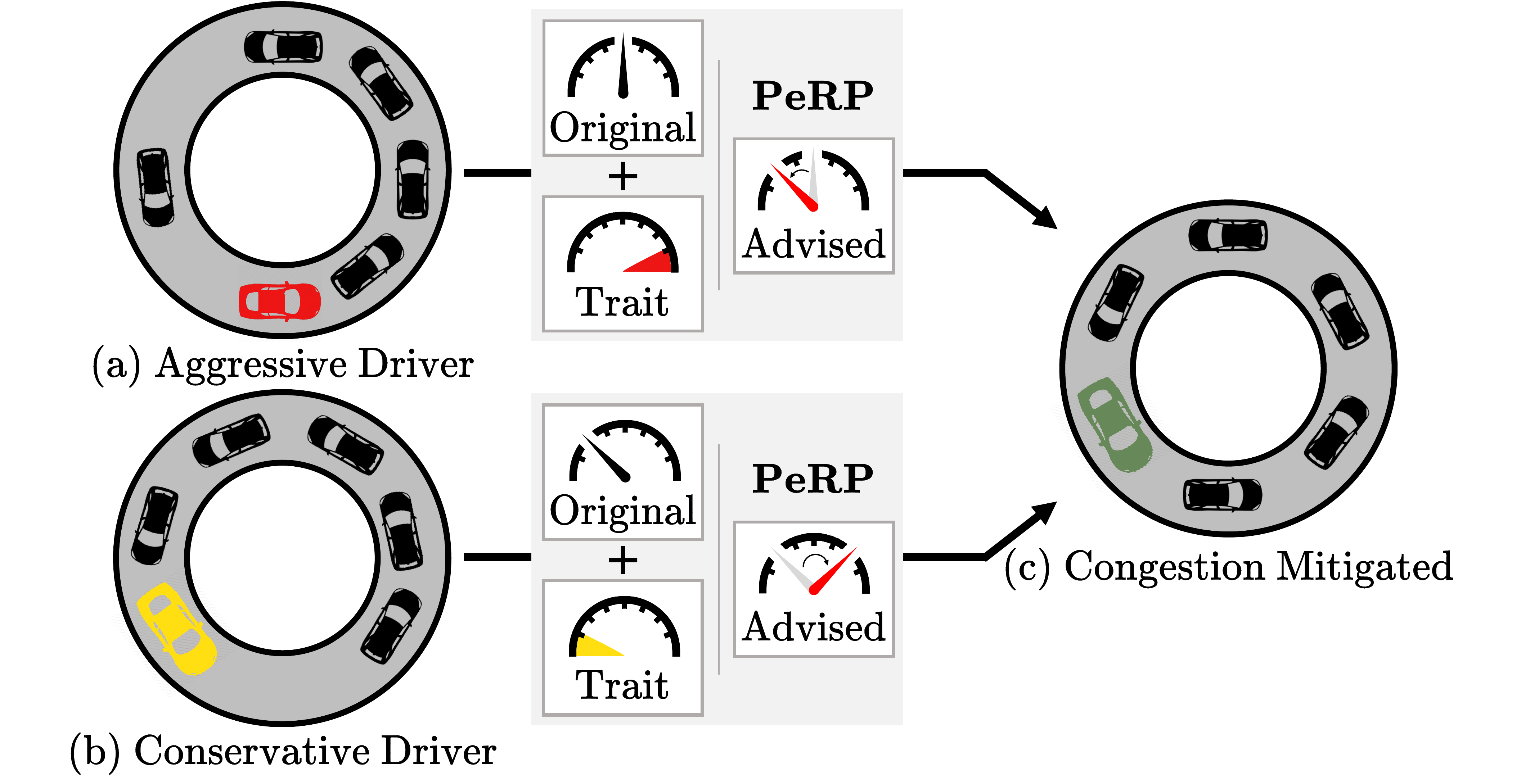
PeRP: Personalized Residual Policies For Congestion Mitigation Through Co-operative Advisory Systems
Aamir Hasan, Neeloy Chakraborty*, Haonan Chen*, Jung-Hoon Cho, Cathy Wu, and Katherine Driggs-Campbell ITSC 2023, [Paper] [Website] Best Presentation Award at CSL Student Conference 2024 |

|
Combining Model-Based Controllers and Generative Adversarial Imitation Learning for Traffic Simulation
Haonan Chen, Tianchen Ji, Shuijing Liu, and Katherine Driggs-Campbell ITSC 2022, [Paper] |
|
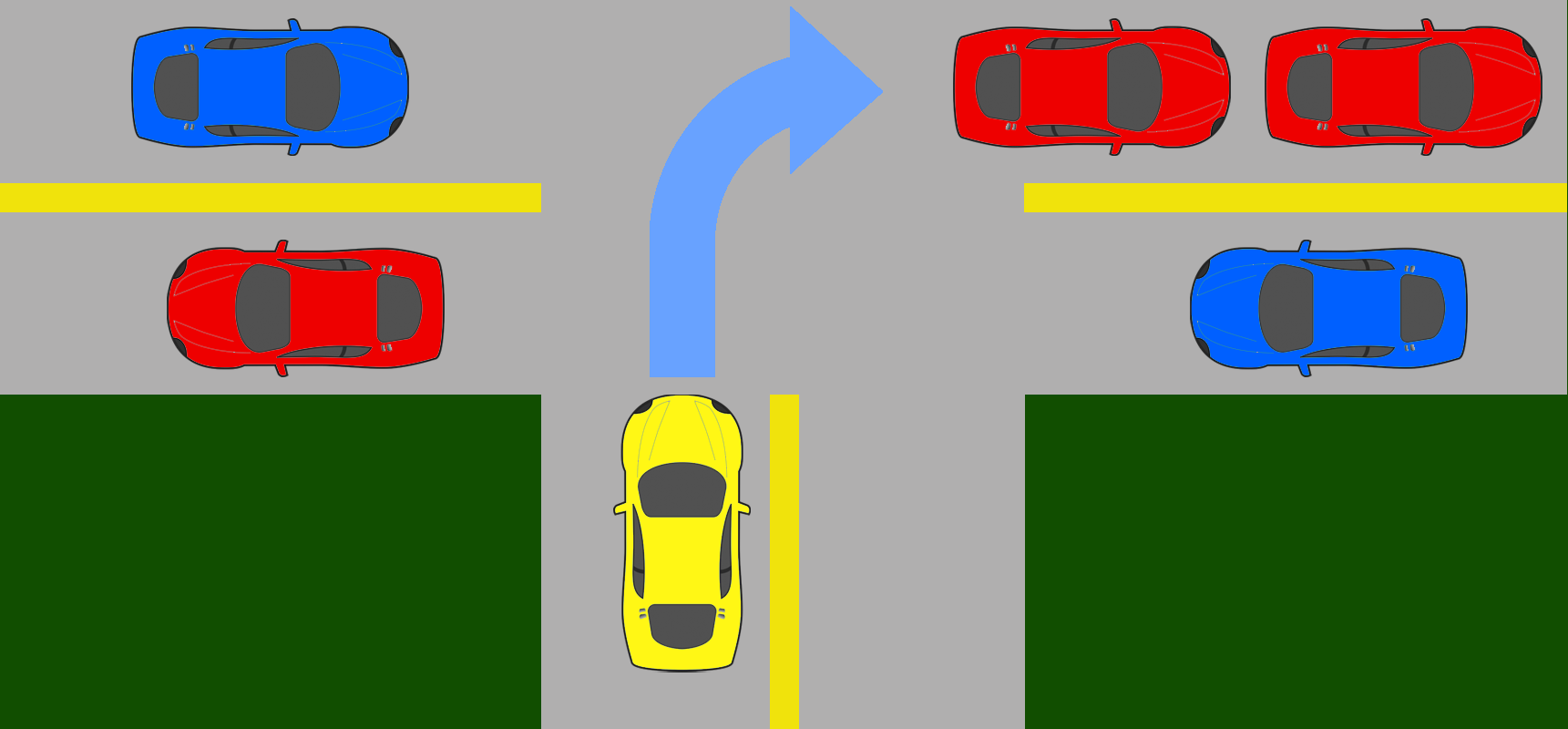
Learning to Navigate Intersections with Unsupervised Driver Trait Inference
Shuijing Liu, Peixin Chang, Haonan Chen, Neeloy Chakraborty, and Katherine Driggs-Campbell ICRA 2022, [Paper] [Website] [Video] |
|
Robot Sound Interpretation: Combining Sight and Sound in Learning-Based Control
Peixin Chang, Shuijing Liu, Haonan Chen, and Katherine Driggs-Campbell IROS 2020, [Paper] [Video] |
Awards and Honors
|
Service and Leadership
|
Professional Service
|
Extra-Curricular ServiceFounding Team Leader, Robotic Team for RoboMaster Challenge, ZJU-UIUC Institute 10/2017 - 06/2018 |